
3.1 人工智能与信息追溯
3.1.1 研究背景
信息追溯在人们的生活中扮演着非常重要的角色,而对于信息追溯的研究却也方兴未艾。机器学习是近年来国内外的研究热点,并能较好的解决各种问题,在各个领域都有不俗的表现。因此利用机器学习方法来解决信息追溯问题具有极强的现实意义以及发展前景。本章综合总结了近年来以机器学习为代表的人工智能技术在信息追溯领域的研究成果,列举了BP和SOM神经网络在工业供应链中的生产预警,SVM在软件设计中的误差预测以及SVM和k-means聚类算法在网络中的流量分析溯源。除此之外,还探讨了计算机视觉、RBF神经网络、决策树等机器学习算法在信息追溯中可能发挥的作用。
3.1.1.1 信息追溯
信息追溯是二十世纪初期提出的概念,旨在实现信息的可追溯性,从而将生产周期、设计环节或是信息的传播过程都限制在可控的稳定状态下。一旦出现偏差,能迅速定位到误差源头并给予及时处理,从而将损害减至最少。在现今社会的方方面面,都有信息追溯的应用背景,并且人们对实现信息可追溯性的需求也日益提升。从最显然的食品安全信息,到软件设计中对用户需求的逐一实现,再到信息传播纷乱迅速的社交网络,信息追溯都在其中扮演着至关重要的角色。可以说,信息追溯的研究与人们对美好生活的热切需要是息息相关的。
关于可追溯性的提出,最早是由上世纪末欧洲出现的“疯牛病”而引起的,这一粮食灾难直接推动了社会各界对食品安全的关注,也促进了人们对食品以及生产原料信息透明化的需求。因此在食品生产供应链这一领域,信息追溯应运而生。为了应对疯牛病事件,欧盟从1997年就开始建立食品质量安全信息追溯体系。不仅从立法角度推进食品信息质量保障,还设立了相关食品安全管理机构,并针对食品安全危机建立了应急制度。而接下来的几年中,对食品信息可追溯性的研究也从欧洲扩展到了世界的其他地区。在2004年,Elise Golan就曾探讨美国的食品安全信息追溯[1],而日本也在同年时间制定了《食品安全基本法》并开始实施,而且也在逐步扩大食品质量安全追溯的范围[2]。甚至非洲也加快了食品信息追溯研究的步伐。斯威士兰和纳米比亚在2016年实现了肉类的可追溯性,不仅让国内的人可以消费到有质量保障的肉,也将这些肉类出口到了欧洲以及世界的其他国家和地区[3]。而近年来,我国的食品安全问题也频繁出现,自然的,食品安全的观念开始深入人心,渐渐地也带动了我国食品行业信息追溯研究的发展。
工业生产中除了食品行业,还有例如纺织业、制造业等许多其他工业类型,由于这些产业的供应链与食品工业生产供应链之间具有极强的相似性,自然对信息追溯的研究也就扩展到了其他各种工业供应链。不过除了工业生产,信息追溯在其他领域也有很广阔的背景。例如在软件设计中,需求分析或是误差检测常常需要通过客户所提出的需求或是捕捉到的误差信号反向追溯到对应的源代码,这种从文档出发检索到代码的过程也是一种信息追溯。另外,在国内由于过大的人口基数以及微博等社交软件日渐流行,我国的社交网络异常复杂。而且信息传递的成本极其微小,这也导致网络中衍生出了不少虚假甚至有害信息。社交网络中的信息追溯也渐渐成为新的研究领域。在这些领域,同样也有很多学者做了相应的研究。
由于应用领域繁多,所以到目前为止,信息追溯还没有一个确切的定义。不少机构、团体或者科研工作者都曾尝试给出一个合适的描述。在1994年,国际标准化组织(International Organization for Standardization, ISO)就曾将其定义为“通过可记录的识别装置来追踪实体的历史、应用过程和位置的能力”[4]。接着在六年后,国际标准化组织又在发布的ISO 9000:2000中对此定义进行了修改,变为“追踪某件物品的历史、应用过程和位置的能力”[5]。另外,在所有ISO提出的这些定义中,都附加了对可追溯性的进一步更细致的阐述,即是对“全部或部分材料的来源、处理过程以及运输之后产品的分配与储存位置”的追溯。
在不同的工业领域,信息追溯有着不同的定义。1997年,粮食与农业组织和世界贸易组织在颁布的《食品法典委员会程序手册》中提出了一个新的定义:“在食品的生产、加工以及流通的特定阶段中,跟踪食品去向的能力”[6]。它进一步点明了“跟踪食品去向”这一要求,却没有提到向后追溯的能力,因而是片面的。T.P.Wilson等在1998年将食品可追溯性定义成“去描述粮食作物的生产过程,以及从农田到餐桌的过程中经历的转化与加工的必要信息”[7]。同样在1998年,T.Moe提出可追溯性是指“在采摘、运输、储存、加工、流通和销售的部分或全部生产链周期中追踪一批产品及其历史的能力”[8]。2002年的《欧盟食品基本法规》则提出,食品工业中的信息追溯是指“在生产、加工和流通的各阶段中回溯或跟踪食品、饲料、食品用动物或是食品与饲料中的其他添加物的能力”[9]。C.Dalvit等人也在2007年提出,对于以畜牧业为基础的食品生产线来说,可追溯性是“在从农场到零售商这个供应链的各个阶段中,都能存储动物或动物制品的各项可靠信息的能力”[10]。
上述定义虽然都在前人研究工作的基础上做出了改进,但是多少还有不到位的地方,或冗长而不精练,或狭义而不普适。面对如此情况,国内外学者都做出了自己的努力,试图总结之前的研究工作,从而给可追溯性一个好的定义。在2013年,Petter Olson等人在总结了之前所有的可追溯性定义,分析了他们的优缺点之后,给出了一个综合的定义“利用可记录的识别装置,获取事物的全生命周期中部分或全部信息的能力”[11]。而在国内,侯博也在2017年发表的综述中提出,追溯的实质是把供应链上的实体流转变成信息流,再根据信息流的正向和反向查询,从而获得实体的历史、应用和位置[12]。在目前的生产供应链信息追溯中,这是两种最为合适的定义。不过他们表达的其实也是同样的意思,“把实体流转变成信息流”实际上就是指的利用识别装置,将实体所携带的各项信息记录下来,而正向与反向查询,也不过是获取信息的手段而已,历史、应用和位置更是显然代表着事物全生命周期中的一部分信息。因此这两种定义可以归纳为一种。不过上述关于信息追溯的定义,都只局限于工业供应链中的信息追溯,没有提到在软件设计和社交网络中的追溯行为。与工业供应链中对实体的追溯不同,这两种信息追溯他们的共同点在于,这里追溯的都是虚拟的信息数据。因此综合以上三个领域,我们可以定义信息追溯为:
信息追溯是关于信息的可追溯性的研究,而可追溯性是指利用可记录的识别装置,获取实体或信息数据的全生命周期中任意信息的能力。
3.1.1.2 机器学习
机器学习则是这篇文章的另一个主题。它是人工智能下属的一个分支,而人们对人工智能的设想古来既有。在很久之前,许多科幻小说中就有了人工智能的影子,它们通常的形象就是具有自主思想能力的机器,这些机器不仅在情节中扮演着重要角色,同时也携带着人们对实现人工智能设想的美好愿景,甚至引发人们对相关社会伦理问题的思考。上个世纪图灵提出,如果人不能分辨他面对的是一台机器还是一个人,那么这个机器就可以被称为是智能的。这个测试也被称为图灵测试,它成为了判断人工智能的最经典的准则。如果一台机器能通过图灵测试,那么它被称为图灵机。世界上公认的第一台图灵机是McCullouch和Pitts在1943年设计的“人工神经元”,而这个神经元模型对后来“连接主义”起到了非常深远的影响,是后来的人工神经网络模型的基石[13]。
十余年后,在1956年的达特茅斯学院研讨会上,麻省理工学院、卡内基梅隆大学和国际商业机器公司(IBM)的几位与会者共同成立了人工智能这个研究领域,也从这时刻起,人工智能正式成为了一门学科。在后来的几十年中,该领域的发展经历过低谷,但最终来到21世纪之后,由于计算能力的提升、样本数据量的大幅增加等多方面因素,人工智能的研究发展迎来了高峰,也在多个领域战胜了人类。人工智能的成功受到了社会各界的广泛关注,这个领域也由此成为了世界范围内当仁不让的研究热点。
机器学习和人工智能总是一起被提到,而且似乎也没有什么区别,但事实上这依然是两个不同的概念。人工智能的任务是要让机器真正变得“智能”,因而能像人一样自主思考来解决问题。而机器学习只是给机器设定一个框架并给予它一定的数据集,让机器从中学习知识获取规律。因此机器学习只是人工智能的一个分支,它是实现人工智能路上重要的一环,但它并不就等于人工智能。
机器学习可以大致分为两类,即监督学习和无监督学习[14]。
监督学习的任务一般来说是预测或者是估计的任务,也就是在给定一个或一组输入的时候,模型能确定一个输出。之所以叫监督学习,是因为用到的数据集中数据都是以“输入-输出对”的形式成对存在的,也就是说当机器获取到输入数据时,样本集合会有一个理想的输出,如果实际的输出与其不符,那么机器就会收到信号从而调整自己的结构以更好地拟合样本数据。就像老师监督学生完成作业一样,监督学习的名字由此得来。
监督学习的方法有几大类。一类是回归类的方法,最早的方式是线性回归,勒让德和高斯于19世纪初提出的最小二乘理论实际上就是线性回归的雏形[14]。后来到20世纪40年代,研究工作者又提出了改进过的逻辑斯蒂回归模型,当然后来又出现了一些关于基函数的回归方法,这些都是回归模型,也是一类基本的监督学习方法。另一大类是在整个机器学习发展史上有着浓墨重彩一笔的神经网络模型,从最早的感知机,到后来的误差反传神经网络、径向基函数网络,再到最近大热的深度网络,都属于人工神经网络的范畴,他们也都属于监督学习。除此之外,一些基于树结构的方法也是监督学习的一个分支,例如决策树、分类回归树等等。这些方法模拟的是人类大脑中对问题不断剖分,一步步做决策的思路过程,因此常用于分类任务。而说到分类任务,还有一种重要的监督学习方法,就是支持向量机。支持向量机曾经一度超越神经网络模型,成为该领域科研工作者的心之所向,不过后来又被深度学习盖过了风头。
一般来说,在机器学习中大部分的任务都是监督学习的任务。不过,无监督学习同样也是非常重要的一部分。无监督学习和监督学习的一个重要差别就是,它的数据集中并没有输出的概念,因此当模型接收了输入之后并没有一个期望的输出,也就是说对模型的训练不存在监督的作用。由于这样的特性,无监督学习面对的任务大都是从给定的数据中发现其中的关系,或者是探究数据的结构[14]。无监督学习最为常见的任务是聚类任务。它和监督学习的分类十分相似,但区别在于分类任务的样本点是有编号的,例如最常见的二分类,每一个样本点都被编号为0或者1,这样在分类任务中只需找到样本空间中的一个最优的超平面,使得所有的样本点按照编号的不同尽可能分布在超平面的两侧。而在聚类中,样本点是没有编号的,所有的样本点“看上去”都没有区别,那么分类的说法也就无从谈起了。那么在这种情况下聚类就只要求从样本数据集的结构入手,发掘出其中的规律。例如当这一块的样本点都集中分布在一块小区域,而与其他的样本相距比较远,那就可以说他们聚集成一个类,或说一簇。常见的聚类算法有K-means,Hierarchical methods等算法,并且有基于距离、层次、密度等不同聚类准则的划分。另一类无监督学习方法是关联规则,它致力于挖掘出数据之间的关联关系。它起源于经典的购物篮问题,即在一家超市的交易数据中,隐藏着商品与商品之间的相关关系,例如买了商品A的顾客有很大可能同时也买了商品B,那么这样就称为一条从A到B的关联规则。常见的算法是Apriori算法。除此以外一些降维方法也被归纳在无监督学习领域,例如耳熟能详的主成分分析方法(Principal Component Analysis,PCA)[14]。
机器学习经历了数十年的长足发展,全世界的科研工作者在这个领域投入了许多的时间和精力,各项研究也日趋成熟。不仅如此,机器学习还在其他领域有很好的应用背景,解决了不少复杂的难题。可以说,利用机器学习方法来解决实际问题将慢慢成为一种趋势,也是未来的主流发展方向。那么对于信息追溯,自然也会想到如何运用机器学习的理论来帮助解决这个领域的问题。事实上在世界范围内,已经有许多专家和学者对此进行了尝试。
3.1.2 国内外研究现状
国外对于信息追溯的研究自从上世纪末就开始了。T.P.Wilson和W.R.Clarke在1998年提出了一个追溯系统的设计和发展的雏形,该系统通过工业管理系统汇总、用户个人自主上传等多种渠道收集数据,保证了食物供应链中的每一个角色对追溯系统的接入和使用,并将为追溯数据的整理、定位和传播提供一个实际的工业标准[7]。在这一年,T.Moe也讨论了追溯系统的基本要点。一个追溯系统最重要的功能是准确识别物体的能力,这也是追溯系统的基石。在系统中,追溯的对象被称为追溯资源单元(Traceable Resource Unit,TRU),如果是按批次处理的过程那TRU就是独一无二的那一批货物,若是连续的处理过程则需要更复杂的讨论才能确定TRU。另外,T.Moe还提出了追溯的分类观点,即分为链追溯和内部追溯两种方式[8]。
Roxanne Clemens在2003年的文章则从让消费者放心这个角度分析了日本的肉类追溯进展。由于地域等限制因素,日本的肉类大部分都来源于国外进口,而疯牛病事件显著地影响到了挑剔的日本消费者对购买肉类的态度。为了安抚消费者,一方面日本政府从立法的角度一再加强对肉类质量的严格控制,另一方面,各大超市与零售商也配合政府推出“有故事的肉”等营销策略来稳定消费者的紧张情绪[15]。Brian Buhr表明在食品供应链复杂程度日益提升的过程中,很少注意保留了有关食品来源及转化过程的信息。他在2003的文章中研究分析了六个配备了追溯系统的欧盟组织,并为美国的肉类工业提供了指导[16]。同年,Linus Opara回顾和总结了农业中信息追溯和追溯管理系统的相关概念,并点明了在实现可追溯农业供应链过程中将面临的技术难点。为了实现可追溯性,合适的识别方法、加工过程的描述、用于储存与信息交互的信息系统还有对可追溯供应链最终的整合都是必不可少的。另外Linus还将农业供应链追溯系统划分成了产品可追溯性、过程可追溯性等六种重要的追溯类别[17]。
在2004年,Jill Hobbs探讨了追溯系统在解决信息不对称问题中发挥的作用。追溯系统通过事前安检功能确保食物的质量,而事后反应功能可以在产品出现问题后实现对污染源的回溯,从而降低产品召回成本。除此之外,事后反应功能还承担起责任分配的任务,有利于事后追责[18]。Elise Golan等人则从成本与收益的角度分析了追溯系统在美国私有食品企业中的发展,并研究了生鲜食品、谷物与油籽以及牛肉等食品的具体案例。作者指出,虽然私有企业制定了多种标准来防止食品安全问题的出现,但是当安全隐患真正发生时,让政府进行调控更为合适。调控的目标基本上在于将出现问题的食品从市场上召回,并且保证企业对于召回方式有一定的自主性和灵活性[1]。
Takeo Takeno及他的团队在2006年将追溯系统分为实体物流层、企业资源规划层(Enterprise Resource Planning,ERP)和独立数据管理层三层。实体物流层将储存原料清单、生产计划等信息,ERP层储存购买、存放、运输等核心商业信息,并且这两层的信息将整合到独立数据管理层上。文中搭建了一个小型的海产品供应链模型,并实现了上述的追溯系统[19]。Dimitris Folinas等人则介绍了一种基于可扩展标记语言(eXtensible Markup Language,XML)技术的追溯系统通用框架,并探讨了为实现高效的食品信息追溯对系统基本数据提出的要求[20]。C.Dalvit则对于畜牧业的供应链信息追溯提出了一种新的观念,他们团队认为纸质文件可以伪造,而DNA等生物信息却是独一无二且不可造假的,因此他们依托DNA分析技术,研究了基于产品识别的基因追溯系统。文章叙述了近年来基因识别在个体、品种和物种级别取得的进展,介绍了它们的优缺点以及在动物生产当中的实际应用。虽然这种设想有发展前景,但是就目前来看,该技术的成本依旧太高,不能投入到实际的产业当中[10]。Herve Panetto等人认为,为了在产品全生命周期中实现可追溯性,必须建立信息系统使得跟产品相关的所有信息都被记录下来。IEC62264标准为企业在商业和制造层面的产品、过程等信息交互定义了一个通用的逻辑模型,因而成为了产品信息追溯的基石。作者将IEC62264标准与Zachman框架相结合,为实现产品可追溯性提供了方法[21]。
Thomas Kelepouris在2007年的文章则在信息追溯中应用了射频识别技术(Radio Frequency Identification,RFID),文章研究了实现可追溯性的条件,讨论了该如何应用RFID技术来满足这些要求,并且从供应链信息追溯可操作性的角度提出了信息数据模型和系统结构[22]。在2009年,M.R. Khabbazi等人探讨了工业控制系统的信息层中为实现可追溯性而必需的数据建模问题,实现了从订单到最终产品过程中任意信息的可追溯性。并且保证了流程中的实时控制能力,从而记录偏差及评估其影响变得容易。作者对于数据模型利用的是概念-实体模型(Entity-Reality,ER),并研究了汽车零部件工业生产的一个实例[23]。同年,Maitri Thakur等人也针对散装谷物供应链展开了追溯研究。为了满足消费者的需求,散装谷物通常会通过混合不同品种得来,而在这个过程中批次的独特编号得不到保留,这也使实现可追溯性变得困难。作者提出了美国散装谷物供应链的信息追溯系统,可以实现链的追溯和内部追溯,并且也为消费者以及供应链各环节之间的信息传递与交互提供了模型,同样也是采用的XML技术[24]。也是在2009年,Wei Zhou认为RFID技术由于其携带产品信息的能力,正在慢慢成为最热门的信息追溯技术。作者将RFID技术应用在了工业制造的环境中,并完成了商品个体级别的信息追溯[25]。Wendy Rijswijk和Lynn Frewer针对可追溯性的需求、首选的信息传播方式、对伪劣商品的处理等多个方面,对来自四个欧洲国家的消费进行了民意调查,总结了民众对接收信息的需要也提出了对实现可追溯性的要求。文章表明,民众对于食品及产品生产过程中的信息有相当大的需求,而严格负责任的追溯系统可以向人们提供这些信息[26]。
2013年,Zhaolin Cheng及他的团队从成本与收益的角度,研究比较了检验控制和追溯控制两种质量控制手段在时装与纺织业中的优劣,并试图达到一个帕累托优化。文章发现,尽管目前检验控制的成本要低于追溯控制,但随着技术的发展进步,追溯控制将在未来获得越来越大的优势[27]。Giuseppe Aiello等人认为,实现追溯系统的关键在于收集各项产品质量相关信息的能力。而随着RFID技术的发展,实时数据自动收集也成为可能,从而高效的信息追溯系统将不再仅仅是一个设想。更进一步的,作者还分析了追溯系统的潜在价值。以生鲜食品(如蔬菜,水果)追溯系统为例,分析了系统的期望收益,并基于RFID技术找出了最优粒度水平,或者说最优的追溯批次大小。与无追溯系统情形下的预期利润进行比较,证实了追溯系统的优越性[28]。
Tania Prinsloo等人在2016年则发表文章为纳米比亚和斯威士兰的追溯系统提出了构想,并应用在了肉类供应链上。案例研究和访谈都表明,系统是可持续的,并且农民也确实从中获取收益。虽然依旧有不少工作未完成,例如收益的全部范围还不甚明确,不过追溯系统的应用已经使人们能吃上并能一直吃上安全放心的肉了[3]。Mattia Mattevi及其团队研究了英国中小型企业食品供应链对于可追溯性的意识与态度,目的是为了探究中小型企业是不是如同一些文献所说,明白可追溯性的主要目标。通过问卷调查的形式,发现各企业都对可追溯性有很好的了解,不过也有理解上的偏差,例如认为追溯系统的实现能减少产品召回的概率。另外,虽然企业普遍承认追溯系统的重要性,但大多不愿意投资在追溯系统的研究与改进上[29]。
2017年,Zhang Zhenxuan等人提出了一种蔬菜追溯信息自动汇总方法,解决了蔬菜信息追溯应用中数据录入过于繁多和成本高的问题,为农民实现了社交网络上的实时信息共享,并达到提升自身品牌,获取更多客户的目的。在文中,作者研究了影响蔬菜可追溯性的因素,并以此确定了关键的指标,结合采摘参数和法律系统建立了数学模型。这种追溯方法已经被越来越多的人接受[30]。Zhipeng Wu及其团队则分析了基于物联网的数字化制造业所面临的挑战,针对机器之间频繁的数据交互提出了一种面向数据的系统结构,为提高协同性设计了灵活的数据结构及数据表示方法,还有产品管理中的多样的信息回溯方法。并且也在数字化食品生产线中得到了很好的应用[31]。
国内对信息追溯的研究虽然起步稍晚,但并不影响国内学者做出非常好的成果。2008年中国农业科学院的曾行及其团队就利用面向对象编程和关系数据库等技术,对于中国的猪肉信息建立了可追溯系统,实现了信息查询、采集和预警等功能[32]。柴毅等人则在2009年利用RFID标识、EAN·UCC成品编码等技术建立了猪肉加工链信息追溯系统,数据采集通过对胴体的识读来实现,并且在屠宰加工环节就能现场获取数据[33]。同样是该团队,2010年他们更进一步对猪肉生产加工信息的追溯系统做了结构层面的分析。他们在文中分析了物流单元在猪肉生产供应链中的个体标识以及追溯信息组成,设计了其在各个环节的标识载体样式,并提出了一种生产质量控制预警机制。最后给出了一个追溯应用实例[34]。
在2011年,王晓平等人对中国的果蔬类农产品信息追溯系统的可行性进行了分析,并且将追溯系统划分成种植基地、批发商、物流过程和零售商四个模块,在逐一实现之后构建了整体系统,也将该系统应用在了具体的实例上。文章使中国果蔬类农产品追溯系统的研究首次向前推进了一大步[35]。2016年沈敏燕及其团队在文献[35]的基础上,依托从农户到消费者的四大模块,建立了全程追溯模型,实现了果蔬类农产品信息在各个环节的向前和向后追溯。由于在物流运输的过程中,需要精确控制车厢温度,因此利用最小二乘原理等方法融合多个传感器数值来估计出精确温度,相比于基本的平均算法取得了较大的成效[36]。
不管是肉类还是果蔬类农产品,这些都是信息追溯在食品工业供应链当中的应用。而在其他的工业类型中,供应链的结构也是大致相似的,自然也能应用信息追溯方法。在2013年就有学者对于汽车制造业中的信息追溯进行了研究。翟靖宇在研究了汽车供应链的信息化流程,还定量分析了RFID技术与供应链收益之间的关系[37]。邹宗峰也在订单信息系统和零部件批次关系的基础上建立了内部和外部追溯系统模型,并能实现产品的质量事前控制及问题产品和问题批次追溯的目标[38]。
而对于可追溯系统的整体研究也不少见。郑火国深入探讨了食品的信息追溯系统。他通过对食品链进行分析,建立了食品信息追溯链的层次模型,研究了模型中追溯链的粒度、关键标识和完整性等要素,也利用事故树方法对该可追溯链进行分析,进而计算故障发生的概率。构建了追溯链之后,作者又提出了食品安全信息追溯系统的逻辑模型,设计了它的总体架构与多平台溯源结构,并分析了实施的关键步骤,最后应用在了脐橙的质量安全追溯中[39]。2014年文斌等人也设计了基于二维码和数据聚合技术的农业产品信息追溯服务系统,为农产品追溯服务的未来发展提供了一种技术上可操作,并且成本上可行的技术方案[40]。2016年,常建鹏在他的硕士论文中也探讨了基于RFID技术的质量追溯系统设计,主要从数据采集系统部署、软件系统设计还有回溯决策策略这三个方面进行了研究。数据采集依托于RFID技术的快速识别,软件系统则能管理公司的基本信息,对于问题产品可以回溯其详细的生产信息,而回溯决策则用于分析质量问题原因,通过贝叶斯决策方法实现了对产品质量的判定[41]。
也有不少学者尝试利用机器学习的知识来解决供应链信息追溯当中的具体问题。2009年Simon Tamayo等人就利用决策方法及其他人工智能理论来解决供应链中的原材料分散问题,通过对危险级别进行分级,能确定最优的产品批次大小,从而极小化问题产品召回的成本[42]。2012年王哲探讨了针对汽车安全气囊质量信息的追溯系统。他利用经典的误差反传神经网络(Back Propagation Neural Networks,BP)和自组织映射神经网络(Self Organizing Maps,SOM)来对安全气囊装配工序中的故障进行信息追溯,利用支持向量机(Support Vector Machine,SVM)和小波分析的技术来分析电机产生的故障,为汽车安全气囊质量信息追溯系统的建立做出了很大的贡献,也为利用机器学习方法解决信息追溯问题提供了一个非常好的例子[43]。张颂则提出,数据融合算法在食品质量信息追溯中发挥着非常重要的作用,不管是数据采集记录,或是故障预警,还是质量追溯中的决策都需要数据融合算法来做支撑。因此提出了基于贝叶斯分类决策的方法应用于鼎丰真食品的质量信息追溯,并取得了良好的效果[44]。2017年邢向阳则提出了西瓜信息追溯的新角度。他利用瓜蒂外围的图像来作为西瓜的唯一标识码,在图像处理方法的支撑下,完成了西瓜的信息追溯[45]。
对于信息追溯的研究,除了集中在各工业供应链中以外,还有少部分致力于解决软件设计或是社交网络信息传递中的问题。2000年G.Antoniol讨论了软件维护中信息检索(Information Retrieval,IR)的应用,主要研究了系统源代码及其相对应的文档之间的追溯链的恢复问题[46]。Maria Storga则在2009年研究了工程设计中的信息追溯框架,作者指出若想使工程设计信息价值最大化,主要依赖于信息的来源、产生过程等记录,这就使得信息的可追溯性显得尤为重要。作者提出了描述追溯实体和操作的语言以及相关的追溯模型,描绘了工程设计信息追溯的初步构想[47]。而信息检索的方法有向量空间模型、詹森香农模型等许多种,于是Rocco Oliveto比较了这些不同模型之间的性能,并且将一种一般用于处理软件维护其他问题的算法应用在这里,发现与其他的信息检索方法相结合能取得较好的效果[48]。2011年Malcom Gethers也做了同样的研究工作,他针对VSM,JS和RTM三种基本的IR方法进行研究,通过实验发现结合了多种方法的复合型方法效果要优于单个方法[49]。而Hamzeh Eyal-Salman也对信息检索技术做出了改进,不仅提高了精度,还增加了检索到的追溯链的数量[50]。
2014年Rohit Mahajan将贝叶斯正则化方法(Bayesian Regularization,BR)应用在软件设计中的误差检测上,大幅减少了软件测试环节的成本。并且将BR方法与神经网络结合起来,效果要优于一般的配备Levenberg-Marquardt(LM)算法或是BP算法的神经网络[51]。Ezgi Erturk同样也在2015年研究了这一问题,不过他提出了一种新的方法AFSIS用于软件误差检测,并且也利用了在该领域常用的人工神经网络(Artificial Neural Networks,ANN)和SVM方法来和AFSIS的效果进行对比[52]。
在社交网络中,信息追溯系统同样也具有强大的现实意义。2009年杨晶等人探讨了社交网络信息溯源系统的构建,文章阐述了溯源系统的意义,也分析了系统的结构层次以及功能需求,最后提出了信息追溯系统具体建设的宏观构想[53]。对于真实的社交网络信息溯源的研究在2012年就出现了。时国华在他的硕士论文中研究了微博的信息溯源以及信息传播面的计算方法。他利用信息传播模型的相关知识还有微博传播模式的特点探究了微博信息的传递,设计了一种信息传递概率计算方法来进行信息传播路径还原,并且提出了一种计算信息传播面的方法。这些理论都在微博数据集的基础上进行了实验验证[54]。杨静及其团队则基于信息溯源的理论,在2016年提出了虚假信息传播控制的方法,通过主题相关性等特征找出发起者,依托文本情感分析等技术找到前期重要参与者,而综合这两方面的信息就能找到信息源头并予以评估。作者在文中提出了具体的控制方法,并利用微博数据集进行了实验,验证了方法的优越性[55]。刘荣叁等人则认为在之前的信息溯源研究中,对用户影响力涉及的因素不是考虑得特别周全。因此作者团队重新设计了评估用户影响力的方法,从而能对具体事件进行信息追溯[56]。宋鸣提出了根据流量分析的技术来进行信息追溯的新思路。在网络流量识别中利用SVM算法来作为分类算法,能以90%以上的正确率和召回率对流量进行分类识别,另外利用k-means聚类算法,对于网络的入口流量和出口进行分析,从而挖掘出其中的对应关系。最后在真实的网络下进行实验,准确率达到了90%以上[57]。
3.2 机器学习与追溯系统
3.2.1 概述
在各种工业的生产供应链中,信息追溯的实现方法或是系统结构可能并不完全相同,但是都遵循相同的基本框架和功能需求。这样做具有很显著的现实意义。一方面,信息追溯发展较为迅速、研究较为成熟的工业可以为其他工业领域的信息追溯提供指导作用,甚至在理想的情况下,追溯系统可以直接迁移到一个新的生产背景中。另一方面也能使学者对于该领域该学科的研究能有一个总体的把握,为信息追溯在将来的研究进展铺平了道路。
如图3-1所示,从结构上来说,追溯系统一般可以分为三层:实体物流层、企业资源规划层(ERP层)和独立数据管理层[19]。实体物流层将储存原料清单、生产计划等信息,ERP层储存购买、存放、运输等核心商业信息,独立数据管理层则对其他两层的信息进行整合和分析,以用于不同目的。独立数据管理层中还会产生公司与公司之间的追溯数据。这三个层虽然互相独立,但层与层之间都有非常完善的信息交互手段。有了完整而全面的层间信息交互,才能将实体流转变为信息流,而可追溯性就将通过信息流来实现。
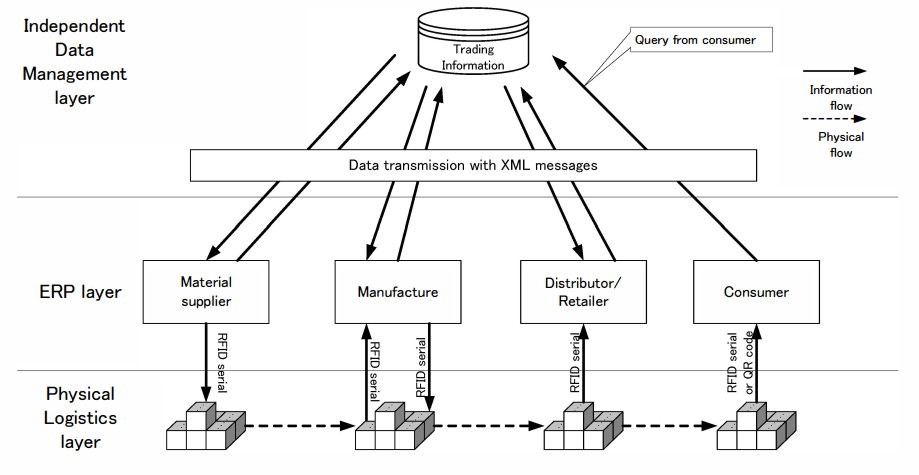
图 3-1 追溯系统的三层[19]
如图3-2所示,追溯系统从功能上来说一般需要具有以下能力。
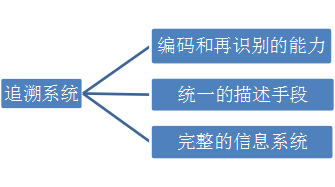
图 3-2 三大能力
(1)编码和再识别的能力
想要实现可追溯性,必然需要将一个个产品实体转化成数字信息,从而能被计算机读取和储存。这实际上是建立了一个产品与编号之间的一一对应关系,给每个产品赋予一个独一无二的编号,这样才能将对产品实体的检索转化成对计算机存储空间中数据的检索。而要对实体赋编号,目前使用最为广泛的方法就是打印喷码。并且随着科技的发展,码的形式也变得不唯一,常见的有条形码、二维码,近年来射频识别技术发展迅猛,因此还出现了RFID,而在将来,很有可能还会出现新的技术……这些都能满足编码和识别的要求,因此也都是建设信息追溯系统的可选方案。
随着研究的不断深入,也出现了其他的编号方式。例如利用生物信息来代替人为设计赋码。对于食品工业来说,不管是蔬果等农作物还是家禽家畜,不会出现两个完全相同的个体,如果能找到外形上独一无二的特征,就能利用图像识别的技术直接将这些实体区分开。或者更进一步,甚至不利用外形特征,而是利用每个个体的遗传信息来作为标识码,这样通过DNA分析技术就能对个体进行识别。利用生物特征信息可以省去编码的麻烦,也能避免赋码过程对于食品的潜在影响。
(2)统一的描述手段
不同的生产供应链之间,对于原料或中间产物要进行的操作自然是不同的,甚至同一产品的供应链,不同公司所使用的方法、材料所经历的操作或过程也可能是完全不同的,那么如果将来要能整合成一个完整的追溯系统的话,自然需要使用结构化统一的语言来描述各种操作和过程。不仅如此,还需要采用计算机能理解的描述。目前来看,常用的方法是可扩展标记语言(eXtensible Markup Language,XML)。
(3)完整的信息系统
信息系统是整个追溯系统的核心,当实体转变为信息数据形式存储在计算机中之后,不管是查询生产中的某一条记录,或者是根据记录下来的信息进行某种分析,用户的任何操作都需要通过信息系统来实现。他一般应当具有对信息的采集、存储、分析、检索和传送等能力。信息的存储、检索和传送都可以通过现阶段已经发展较成熟的数据库等计算机技术来实现,其余的两种则是当前研究的重点。
信息的采集依托于编码和识别技术的发展。条形码和二维码都是最早的喷码形式,也是使用最广泛的形式。通过编码,商品的生产时间、产地等各种信息都被储存在计算机中,通过特殊的识别设备读取这些码,就能够获得该商品的相应信息,才能够让这些信息为我们所用。而不断发展的新技术,如RFID,也将带来新的进步与突破。例如RFID由于识别方式的特殊性,不需要刻意将识别设备对准标识码,从而能使得数据自动采集变得现实[28]。而随着人们的思路慢慢转移向放弃编码赋码而直接采用生物特征时,就将带来更多的益处,更加使信息采集变得快捷。不过这也对图像处理或者DNA分析等技术提出了非常高的要求。
信息的分析则是信息系统的核心所在,如果没有对收集来的数据信息进行分析的功能,那么就系统就仅仅与一块存储空间无异。信息系统的分析功能主要有预警、决策等方面。预警任务其实就是误差检测,利用收集的数据检测生产系统中是否有部件或是环节出现了偏差,从而予以矫正。这样能在生产系统中就排除危险因素,把问题扼杀在摇篮中,同时也避免了事后再统一召回问题产品的麻烦。而决策实际上是通过对数据进行分析之后,决定该如何处理,例如产品质量判定等现实问题。
而机器学习在生产供应链追溯系统中的应用主要体现在信息的采集和分析方面。对于赋码类型的信息采集通常有相应的识别方式和识别设备,不论是利用光线还是电磁波的方式,技术都已经较为成熟。而如果是生物特征的话,则经常要面临图像处理的问题。利用生物特征作为唯一标识码是非常理想的想法,在实际操作中必然要遇到图像识别、图像去噪、图像分割、特征提取等一系列的问题,因此可以利用计算机视觉的方法来解决这些困难。
而信息的分析中往往会出现分类、决策任务,这些任务也都有很多机器学习算法可以很好的完成。神经网络、支持向量机、贝叶斯决策等等,都是该领域常见的方法,并且也在诸多学者的实验中取得了非常好的效果。
3.2.2 人工神经网络理论
人工神经网络(Artificial Neural Networks,ANN)可以说是近年来出现频率非常高的词了,不仅出现在各个领域,也确实解决了各种问题,从而吸引了非常多的学者投身于神经网络的研究,而这又进一步促进了该领域的发展。
人工神经网络本质上模拟的是人类神经系统的思维方式。在人类进化的数万年中,神经系统已经演化出了足够强大的功能,也因此将我们送上了食物链的顶端。如果能用计算机模拟出人类神经系统,那么它也将具有超乎想象的强大功能,且不说为我们的生活带来多大的便利,更是在实现人工智能的路上迈进了一大步。若是从单个神经元开始用计算机模拟,再把神经元联结起来,就可能实现神经系统的诸多功能。如图3-3所示。
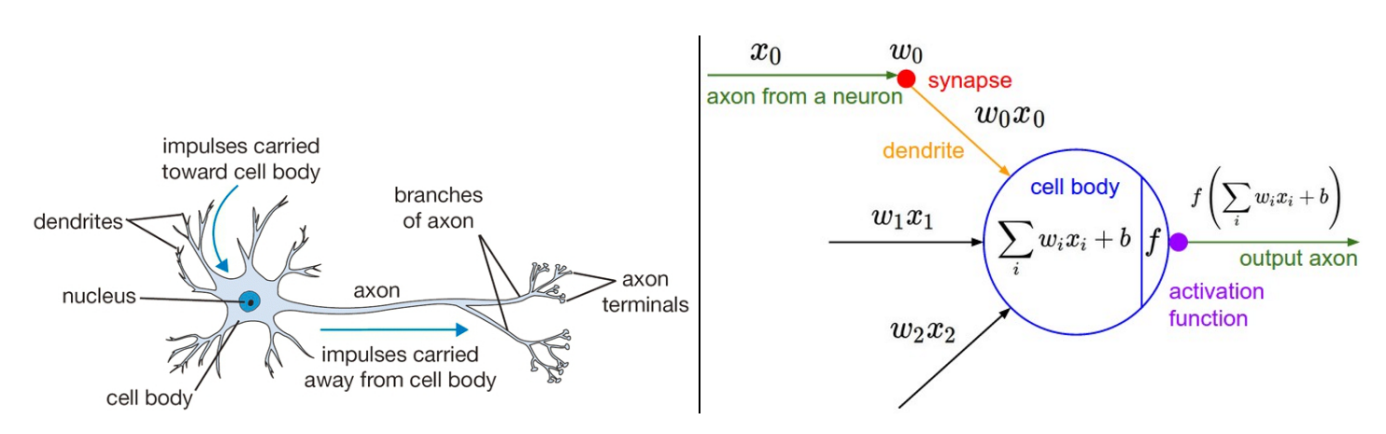
图3-3 神经系统与人工神经元的对比
对神经网络的研究需要追溯到上个世纪40年代。1943年,Warren McCulloch和Walter Pitts首次提出人工神经网络的概念和单个人工神经元的数学模型[58]。而在后来的1957年,美国的神经学家Frank Rosenblatt则完善了这个设想,在M-P神经元的基础上提出了感知机(Perceptron)的模型[59]。感知机可以理解为是单层的神经网络。它的出现意义重大,是整个神经网络理论的基石。
感知机是一种二分类的线性分类器。以向量形式输入样本的特征,能够输出样本的类别,这模拟的是神经元接收到不同的刺激而向后传递出不同的电信号。如果输入空间是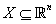 ,其中
,其中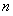 表示特征的个数,那么输出空间就是
表示特征的个数,那么输出空间就是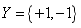 (或者
(或者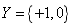 ),如果以
),如果以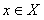 表示样本,以
表示样本,以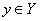 表示样本所属的类,那么感知机就可以表示为如下从
表示样本所属的类,那么感知机就可以表示为如下从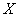 到
到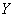 的函数如公式3-1所示。
的函数如公式3-1所示。
|
|
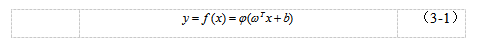
其中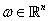 是权重向量,而
是权重向量,而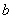 是偏置,他模拟的是神经元的阈值机制,即刺激达到一定的门限才会触发神经元的电位。
是偏置,他模拟的是神经元的阈值机制,即刺激达到一定的门限才会触发神经元的电位。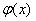 是激活函数(Activation Function),目的是判断输入是否达到阈值,从而“激活”神经元。单个感知机的激活函数通常可以采用符号函数(公式3-2和图3-4所示)。
是激活函数(Activation Function),目的是判断输入是否达到阈值,从而“激活”神经元。单个感知机的激活函数通常可以采用符号函数(公式3-2和图3-4所示)。
|
|

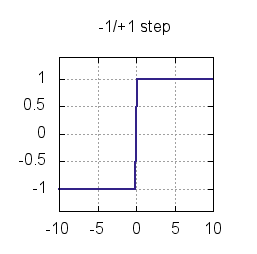
图3-4 符号函数
感知机的结构如图3-5所示。
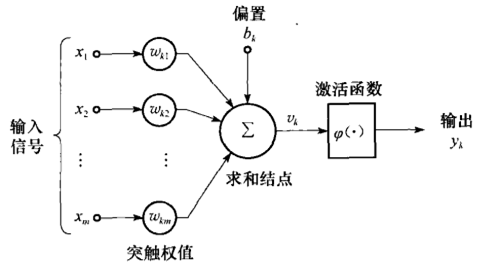
图3-5 感知机结构
感知机是一个线性分类器,这表明感知机它实际上是样本空间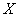 中的一个超平面,我们要做的就是尽可能的使得标号分别为
中的一个超平面,我们要做的就是尽可能的使得标号分别为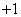 和
和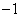 的两类点落在超平面的两侧。而如何判定优劣,就引出了损失函数的概念(Loss Function)。损失函数在机器学习领域中通常衡量一个模型的“犯错程度”,对于作为分类器要解决二分类任务的感知机来说,损失函数可以定义成所有误分类的点到超平面的距离之和,如公式3-3所示。
的两类点落在超平面的两侧。而如何判定优劣,就引出了损失函数的概念(Loss Function)。损失函数在机器学习领域中通常衡量一个模型的“犯错程度”,对于作为分类器要解决二分类任务的感知机来说,损失函数可以定义成所有误分类的点到超平面的距离之和,如公式3-3所示。
|
|
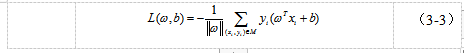
其中 表示所有误分类点
表示所有误分类点 的集合。利用梯度下降等优化算法极小化损失函数就完成了单层感知机的训练过程。
的集合。利用梯度下降等优化算法极小化损失函数就完成了单层感知机的训练过程。
在后来的不断研究中,人们发现单层的感知机只是一个线性的分类器,因此也有很多的局限,例如他不能解决异或问题等的分类。于是慢慢的引入了多层感知机(Multilayer Perceptron,MLP)的概念,这也是神经网络的雏形。多层感知机的想法来源于神经系统。人类的神经系统从不依靠单个神经细胞工作,都是多个神经元互连成网络协同工作,从而作为一个整体接受输入或是给出输出。而将多个单层感知机连接在一起就是MLP的概念。他的网络结构如图3-6所示。
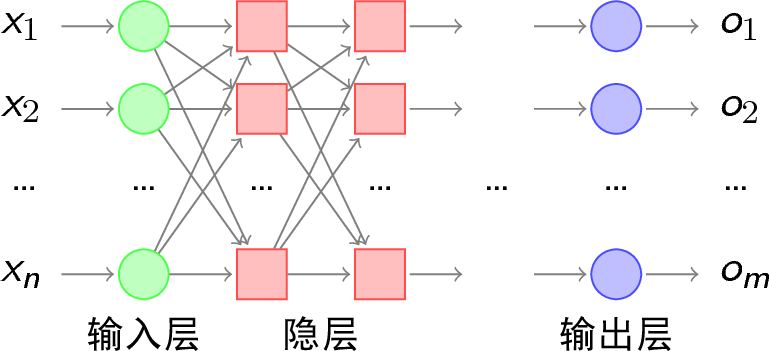
图 3-6 多层感知机结构
多层感知机的网络分为三部分,即输入层、隐层和输出层。其中输入层和输出层都分别只有一层,而隐层则可以有一个或多个。随着隐层个数的增加,网络的学习能力也随之提升。多层感知器的输入层和单层感知机一样,节点个数![]() 等于输入空间的维数,接受到输入之后会经历类似于单层感知机的一套运算,即乘以权值、加上偏置、再经过激活函数的映射,得到一个输出。只是这个输出会成为下一层的输入。例如,有
等于输入空间的维数,接受到输入之后会经历类似于单层感知机的一套运算,即乘以权值、加上偏置、再经过激活函数的映射,得到一个输出。只是这个输出会成为下一层的输入。例如,有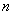 个输入层节点,那么就有
个输入层节点,那么就有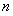 个输出,隐藏层的每一个节点分别都会接收这
个输出,隐藏层的每一个节点分别都会接收这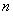 个值作为输入,然后经历同样的运算,得到输出再传递给下一层。
个值作为输入,然后经历同样的运算,得到输出再传递给下一层。
这样可以由单层感知机的模型直接写出多层感知机的公式。以最简单的,隐层数为1的三层感知机为例,假设输入空间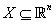 ,输出空间
,输出空间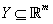 ,则三层感知机模型是从
,则三层感知机模型是从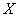 到
到![]()
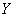 的函数(公式3-4所示)。
的函数(公式3-4所示)。
|
|
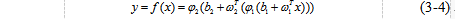
其中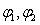 分别表示输入层和隐层的激活函数,
分别表示输入层和隐层的激活函数,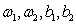 分别代表输入层和隐层的权重和偏置。需要注意的是,多层感知机的激活函数一般都不能再选取例如符号函数或是阶跃函数这样的分段函数,因为多层感知机的学习算法通常采用误差反向传播算法(Back Propagation,BP),而这要求激活函数是可导的,显然符号函数在零点处并不可导,自然也就不再适用。多层感知机中常见的激活函数有Sigmoid函数(公式3-5和图3-7所示)
分别代表输入层和隐层的权重和偏置。需要注意的是,多层感知机的激活函数一般都不能再选取例如符号函数或是阶跃函数这样的分段函数,因为多层感知机的学习算法通常采用误差反向传播算法(Back Propagation,BP),而这要求激活函数是可导的,显然符号函数在零点处并不可导,自然也就不再适用。多层感知机中常见的激活函数有Sigmoid函数(公式3-5和图3-7所示)
|
|
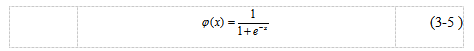
图 3-7 Sigmoid函数
或是ReLU函数(公式3-6和图2-8所示)。
|
|
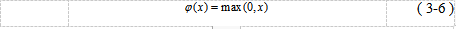
另一方面,如果在多层感知机中依旧选择线性激活函数,那么不管增加多少层,最终复合起来也不过依旧是线性函数。因此从这个角度看,为了让网络的学习能力有质的提升,自然应该选择非线性激活函数。
在确定了网络的结构以后,需要利用适当的学习算法来训练多层感知机,这样才能用来解决实际问题。在众多学习算法中,误差反向传播算法(BP)占据了极为重要的地位。上世纪80年代,BP算法的提出改变了连接主义研究领域的低潮,复兴了学界对人工神经网络的研究。直到现在,BP神经网络仍然是最为经典和重要的网络。
图3-8 ReLU函数
BP神经网络本质上并不是一个新的网络,他只是应用BP算法作为学习算法的多层感知机。神经网络是一种监督学习的方法,这意味着对于样本数据来说存在期望输出,那么BP算法的思想就是利用输出层的实际输出和期望输出的差值来调整网络中的各项权值。而误差反向传播的名字则来源于BP算法的两个阶段,信息的正向传播和误差的反传。信息的正向传播就是多层感知机中的信息流,误差反向传播则是将预测的误差(即期望输出减去实际输出)从输出层开始,向后依次传递给隐层和输入层,并将误差平均分摊给各个节点,再利用梯度下降的原理对各项权值进行修正。BP神经网络的具体流程如图3-9所示。

图3-9 BP神经网络具体步骤
BP神经网络的提出再一次促进了神经网络的发展,这也带动世界范围的科研工作者对神经网络模型的研究。在BP网络之后,不断有人提出了新的神经网络模型。例如径向基函数神经网络(Radial Basis Function Neural Networks,RBF Neural Networks),自组织映射神经网络(Self-Organizing Maps)等等。径向基函数网络的原理类似于基函数插值,所以他和BP网络相同,往往都能够处理拟合问题。并且一般来说,BP网络和RBF网络的效果没有太大的差别。而SOM网络则不同于以上的BP网络或是RBF网络,他是一种非监督学习的方法,通常用于聚类任务,如图3-10所示。
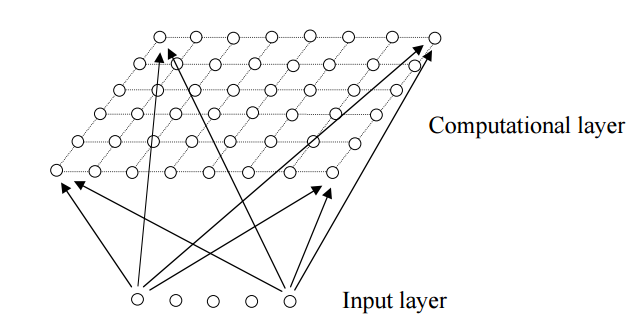
图3-10 SOM神经网络的结构
SOM网络本质上是一种只由一个输入层和一个竞争层组成的网络,而这两层之间保持全互连结构,竞争层的每一个节点都代表要聚成的一个簇。网络的学习采用的是“竞争学习”的策略,即需要不断从竞争层节点中挑选出胜出的神经元。之所以采用这样的策略,是因为人的神经网络在接受外界输入时,会分成不同的区域并给出不同的响应,例如人对狗和猫的概念就存在不同的区域。而SOM模仿的正是这一点。训练SOM网络的具体步骤是:
(1)每个节点随机初始化自己的参数,每个节点的参数个数与输入向量的维数相同。
(2)对于每一个输入样本,都找到与它最相匹配的节点,这里可以用欧氏距离等指标。
(3)更新优胜节点及邻近节点的参数,邻近节点的更新程度随着与优胜节点距离的增加而降低。
3.2.3 基于BP和SOM神经网络的汽车安全气囊装配故障诊断
安全气囊在汽车工业中占据着重要的地位,他直接保护着乘车人员的安全,是汽车安全性能的主要体现。随着汽车的快速普及,对汽车安全气囊的质量严格把控也变得不可或缺。在汽车安全气囊装配工序中,通常采用的方法是在生产过程中进行故障预警,关键的参数(例如气囊的尺寸)一旦出现偏差超过设定的阈值,就会触发警报,从而对故障进行修正排除。
然而对故障的观测是通过若干个传感器来实现的。每个传感器采集到的数据汇总到信息系统中,融合成一个信号模式,那么一个信号模式就可以用来描述整个安全气囊装配供应链的一种状态,可能是正常也可能是故障。那么如果将多个传感器形成的信号模式当成样本空间的![]() 维输入向量的话,那么每个向量都应该存在一个期望的输出:正常或是故障。这样就将安全气囊装配故障诊断转变成了一个二分类问题,从而可以通过机器学习的方法来求解。通过采集足够的数据,就可以对神经网络进行训练,这样网络在今后再一次接受到多个传感器上传的信号数据,也就是一个新的输入向量时,他就能根据之前训练过程中学到的知识来判断这样一个装配状态是正常还是出现了故障。这一点可以通过BP神经网络做到。而在实际生产过程中,只得到“发生故障”这一信息是不够的,往往需要知道故障的具体类型,因此希望网络能对输出向量有一个判断,能够判定该输出属于哪一种故障类型。而这种对聚类的能力是SOM神经网络的特点。因此结合BP和SOM神经网络,就能很好的完成安全气囊生产链中的故障检测。
维输入向量的话,那么每个向量都应该存在一个期望的输出:正常或是故障。这样就将安全气囊装配故障诊断转变成了一个二分类问题,从而可以通过机器学习的方法来求解。通过采集足够的数据,就可以对神经网络进行训练,这样网络在今后再一次接受到多个传感器上传的信号数据,也就是一个新的输入向量时,他就能根据之前训练过程中学到的知识来判断这样一个装配状态是正常还是出现了故障。这一点可以通过BP神经网络做到。而在实际生产过程中,只得到“发生故障”这一信息是不够的,往往需要知道故障的具体类型,因此希望网络能对输出向量有一个判断,能够判定该输出属于哪一种故障类型。而这种对聚类的能力是SOM神经网络的特点。因此结合BP和SOM神经网络,就能很好的完成安全气囊生产链中的故障检测。
根据文献[43]的研究,在安全气囊装配工序中一共有五个传感器,分别是左右侧光栅尺传感器、左右卷袋机速度传感器和压力传感器,每个传感器有8种状态:平稳、上升、快升、下降、快降、升降、未知、异常。于是先利用BP神经网络对每个传感器的状态进行识别,得到五个传感器的状态,再将他们作为SOM网络的输入,判断故障的具体类型。具体步骤如下:
①对于每个传感器,采集他的多个时间序列。
②将时间序列作为BP神经网络的输入,从而得到每个传感器的状态。
③将每个传感器的状态输入SOM神经网络,并将输出结果聚成五类,分别对应五种故障类型。
整个安全气囊装配故障检测的流程可以用图3-11表示。
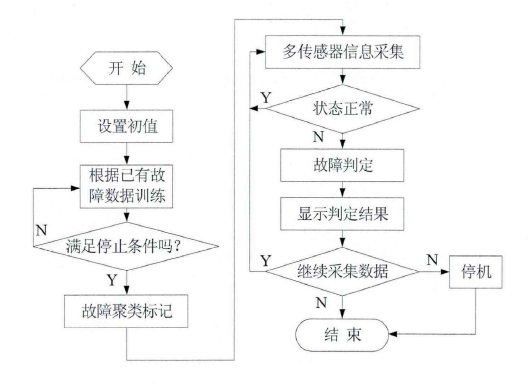
图3-11 故障检测流程[43]
经过实验发现,在300个故障样本数据中,SOM网络能够正确分辨其中295组的故障类型,预警正确率超过98%,充分说明了基于BP和SOM神经网络的汽车安全气囊装配故障诊断方法的有效性。
3.3 机器学习的潜在应用
机器学习在信息追溯领域的应用思路一般来说分为工业生产、软件设计和社交网络中的信息追溯三个方向。
在工业生产中,机器学习主要被应用于信息的采集和分析环节。在信息的采集中,二维码和条形码等传统的码有专门的识别装置,可以完成迅速而准确的完成识别,而生物特征则需要通过计算机视觉的方法才能采集到信息。计算机视觉除了利用传统的图像处理方法之外,还有卷积神经网络等机器学习方法也能同样对图像进行识别。对信息进行分析时,机器学习一般被用来支撑决策或是预警任务。预警对应于回归任务,而决策常依托分类算法解决。BP、SOM神经网络都曾被用来解决这些问题。
软件工程中也有许多信息追溯的需求,不管是设计中的需求追溯还是维护中的误差分析,都免不了要进行信息追溯。对软件进行误差预测时,将软件的状态抽象成输入向量,再根据故障状态给予标记,就可以利用合适的分类算法根据软件状态而对是否出现误差进行分类。SVM是一种非常高效的分类器,自然被学者提出用于误差诊断。
信息追溯还被应用在社交网络中。虚假信息在社交网络中的传播可能会带来非常大的负面影响,为了控制信息传播防止其扩散,快速准确地追溯到信息源头是非常重要的一环。在网络信息追溯中,SVM可以对流量进行识别,而聚类算法k-means则将入口流量和出口流量中具有相似模式的数据发掘出来。
在过去的近二十年中,国内外的学者对于机器学习在信息追溯领域的应用做了不少的研究,对今后的工作起到了很好的指导作用。然而机器学习派别众多,方法繁杂,学者们也只总结了少部分方法。有许多机器学习方法同样也适用于信息追溯领域,运用这些方法来解决问题或许可以为今后的研究提供新的思路。
利用机器学习方法来解决信息追溯的大致思路有三个方向:信息采集环节的物码识别,信息分析中的预警或是决策。
3.3.1 物码识别
在信息的采集中,物码识别是一个很重要的环节,对于非二维码或者条形码的生物特征来说,必须要采用图像识别的方法才能很好的解决问题。图像处理并不是一个新的学科,在长期的发展过程中,他有自身的一套方法。但随着机器学习的迅猛发展,机器学习方法被用于解决各种问题,也都取得了不错的成果,于是慢慢的机器学习也在图像处理领域有了自己的一席之地。利用机器学习来解决图像处理问题,通常就被称为计算机视觉。
人工神经网络是计算机视觉中常用的一类方法,一种高效的方法是卷积神经网络(Convolutional Neural Network, CNN)等。如图3-12所示,CNN是深度学习的一种,在储存和计算能力获得大幅提升之后,深度学习逐渐被用来解决各领域的问题,CNN作为一种深度神经网络,在图像处理方面取得了非常好的成绩,也象征着利用机器学习来进行图像处理的新思路。
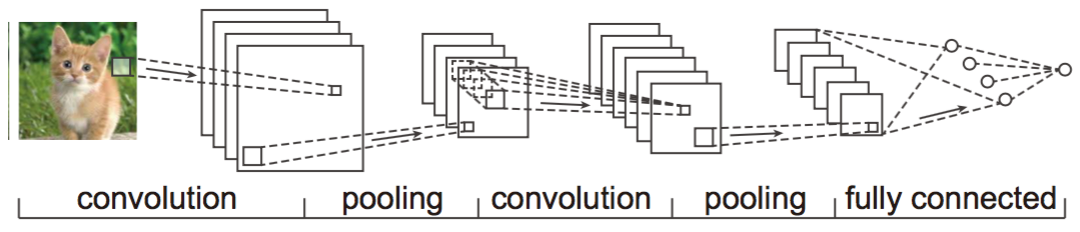
图 3-12 CNN网络的结构
CNN是一种前馈型神经网络,它含有输入层、若干个卷积层、线性整流层(即使用ReLU函数作为激励函数)、池化层和全连接层。卷积层的目的在于特征提取,而池化层则是一种降采样的形式,他不仅能在一定程度防止过拟合,还能有效降低存储量。
3.3.2 预警
预警本质上是一个回归任务,要求模型能尽可能准确的模拟整个供应链的生产模式,这样一旦哪处出现异常,就可以被识别出来,从而将误差减小到最低。
有不少学者已经尝试利用BP神经网络来解决这个问题,然而除了经典的BP神经网络,还有不少其他类型的网络也能完成同样的任务,例如径向基函数网络(Radial Basis Function Neural Networks,RBF)。RBF神经网络借鉴的是基函数插值的思想。径向基函数指的是沿径向对称的函数,最为常用的是高斯函数(公式3-7所示)。
|
|
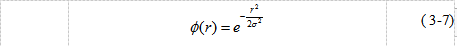
如果用径向基函数作为隐层的基本构成单元,这样输入向量经过隐层的变换,就能模拟基函数插值的形式,从而完成拟合任务。
3.3.3 决策
信息系统在收集到信息之后的分析过程中,常常需要做出决策,而决策的过程通常来说是作为分类问题来解决的。分类任务有许多学者都提出了利用SVM来进行分类的思路。而事实上,分类器还有许多种不同的算法,他们都可以用于支持信息系统的决策。
决策树就是这样一种算法。他是一种树结构,如他的名字所描述,他模拟的是人脑遇到问题进行决策的过程,如图3-13所示。
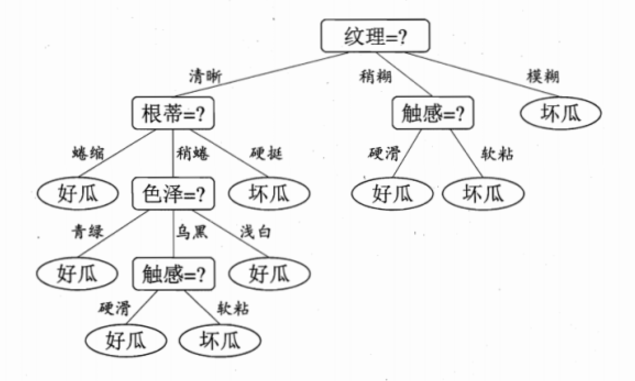
图 3-13 决策树示例
参考文献
[1] E.H.Golan, B.Krissoff, F.Kuchler, et al. Traceability in the US food supply: economic theory and industry studies [R]. United States Department of Agriculture, Economic Research Service, 2004.
[2] 赵荣,陈绍志,乔娟. 美国_欧盟_日本食品质量安全追溯监管体系及对中国的启示[J].世界农业,2012,14(3):1-4
[3] T.Prinsloo, C.De.Villiers. Traceability systems in Swaziland and Namibia: Improving access to markets with digital information[C]//IST-Africa Week Conference, 2016. IEEE, 2016: 1-13.
[4] International Organization for Standardization. ISO 8402: 1994: Quality Management and Quality Assurance-Vocabulary [M]. International Organization for Standardization, 1994.
[5] International Organization for Standardization. ISO 9000: 2005 Quality management systems. Fundamentals and vocabulary [J]. British Standards Institution, 2005, 58.
[6] Codex Alimentarius Commission. Hazard analysis critical control point (HACCP) system and guidelines for its application [J]. CAC/RCP 1-1969, 1997.
[7] T.P.Wilson, W.R.Clarke. Food safety and traceability in the agricultural supply chain: using the Internet to deliver traceability [J]. Supply Chain Management: An International Journal, 1998, 3(3): 127-133.
[8] T.Moe. Perspectives on traceability in food manufacture [J]. Trends in Food Science & Technology, 1998, 9(5): 211-214.
[9] Parliament E U, Council E U. Regulation (EC) 178/2002[J]. Official Journal of the European Communities L, 2002, 31: 1-24.
[10] C.Dalvit, M.C.De.Marchi. Genetic traceability of livestock products: A review [J]. Meat Science, 2007, 77(4): 437-449.
[11] P.Olsen, M.Borit. How to define traceability [J]. Trends in food science & technology, 2013, 29(2): 142-150.
[12] 侯博. 信息不对称, 可追溯性与我国食品可追溯体系考察[J]. 江南大学学报: 人文社会科学版, 2017, 16(5): 123-128.
[13] Russell Stuart J; Norvig Peter (2009). Artificial Intelligence: A Modern Approach (3rd ed). Upper Saddle River, New Jersey: Prentice Hall. ISBN 0-13-604259-7.
[14] G.James, D.Witten, T.Hastie, et al. An introduction to statistical learning [M]. New York: springer, 2013.
[15] R.L.B.Clemens. Meat traceability and consumer assurance in Japan [J]. 2003.
[16] B.L.Buhr. Traceability and information technology in the meat supply chain: implications for firm organization and market structure [J]. Journal of Food Distribution Research, 2003, 34(3): 13-26.
[17] L.U.Opara. Traceability in agriculture and food supply chain: a review of basic concepts, technological implications, and future prospects [J]. Journal of Food Agriculture and Environment, 2003, 1: 101-106.
[18] J.E.Hobbs. Information asymmetry and the role of traceability systems [J]. Agribusiness, 2004, 20(4): 397-415.
[19] T.Takeno, A.Okamoto, M.Horikawa, et al. Development of traceability system for attribute information identification[C]//Technology Management Conference (ICE), 2006 IEEE International. IEEE, 2006: 1-8.
[20] D.Folinas, I.Manikas, B.Manos. Traceability data management for food chains [J]. British Food Journal, 2006, 108(8): 622-633.
[21] H.Panetto, S.Baïna, G.Morel. Mapping the IEC 62264 models onto the Zachman framework for analysing products information traceability: a case study [J]. Journal of Intelligent Manufacturing, 2007, 18(6): 679-698.
[22] T.Kelepouris, K.Pramatari, G.Doukidis. RFID-enabled traceability in the food supply chain [J]. Industrial Management & data systems, 2007, 107(2): 183-200.
[23] M.R,Khabbazi, N.Ismail, M.Y.Ismail, et al. Data modeling of traceability information for manufacturing control system [C]//Information Management and Engineering, 2009. ICIME'09. International Conference on. IEEE, 2009: 633-637.
[24] M.Thakur, C.R.Hurburgh. Framework for implementing traceability system in the bulk grain supply chain [J]. Journal of Food Engineering, 2009, 95(4): 617-626.
[25] W.Zhou. RFID and item-level information visibility [J]. European Journal of Operational Research, 2009, 198(1): 252-258.
[26] W.V.Rijswijk, L.J.Frewer. Consumer needs and requirements for food and ingredient traceability information [J]. International Journal of Consumer Studies, 2012, 36(3): 282-290.
[27] Z.Cheng, J.Xiao, K.Xie, et al. Optimal product quality of supply chain based on information traceability in fashion and textiles industry: an adverse logistics perspective [J]. Mathematical Problems in Engineering, 2013, 2013.
[28] G.Aiello, M.Enea, C.Muriana. The expected value of the traceability information [J]. European Journal of Operational Research, 2015, 244(1): 176-186.
[29] M.Mattevi, J.A.Jones. Traceability in the food supply chain: Awareness and attitudes of UK Small and Medium-sized Enterprises [J]. Food Control, 2016, 64: 120-127.
[30] Z.Zhenxuan, P.Minjing. Automatic summary generating technology of vegetable traceability for information sharing [C]//IOP Conference Series: Earth and Environmental Science. IOP Publishing, 2017, 69(1): 012068.
[31] Z.Wu, Z.Meng, J.Gray. IoT-Based Techniques for Online M2M-Interactive Itemized Data Registration and Offline Information Traceability in a Digital Manufacturing System [J]. IEEE Transactions on Industrial Informatics, 2017, 13(5): 2397-2405.
[32] 曾行, 杨中平, 潘家荣. 基于 Web 的猪肉安全信息可追溯系统的开发[J]. 农机化研究, 2008 (4): 105-107.
[33] 柴毅, 牛楠, 屈剑锋, 等. 基于 RFID 和条码技术的猪肉加工链信息可追溯系统设计与实现[D]. , 2009.
[34] 张可, 柴毅, 翁道磊, 等. 猪肉生产加工信息追溯系统的分析和设计[J]. 农业工程学报, 2010 (4): 332-339.
[35] 王晓平, 安玉发. 果蔬类农产品物流信息追溯系统的构建研究[D]. , 2011.
[36] 沈敏燕, 邵举平, 翁卫兵, 等. 基于数据融合的果蔬类农产品物流信息溯源研究[J]. 科技通报, 2016 (2016 年 11): 233-238.
[37] 翟婧宇. 基于 RFID 的汽车供应链质量信息追溯研究[D]. 上海交通大学, 2013.
[38] 邹宗峰, 孙雪华. 基于物联网技术的汽车零部件追溯信息系统研究[J]. 自动化技术与应用, 2013 (4): 51-57.
[39] 郑火国. 食品安全可追溯系统研究[J]. 北京: 中国农业科学院, 2012.
[40] 文斌, 梁鹏, 罗自强. 基于 QR 二维码和数据聚合的农业产品追溯服务系统设计[J]. 小型微型计算机系统, 2014, 35(2): 261-265.
[41] 常建鹏. 基于射频技术的质量回溯系统设计[D]. 电子科技大学, 2016.
[42] S.Tamayo, T.Monteiro, N.Sauer. Deliveries optimization by exploiting production traceability information [J]. Engineering Applications of Artificial Intelligence, 2009, 22(4-5): 557-568.
[43] 王哲. 基于多传感器信息融合的汽车安全气囊质量追溯系统[D]. 长春工业大学, 2012.
[44] 张颂. 鼎丰真食品质量追溯系统设计与数据融合算法[D]. 长春: 吉林大学, 2013.
[45] 邢向阳, 刘峰, 高俊祥. 基于生物特征纹理信息的西瓜追溯标识算法设计与实现[J]. 农业工程学报, 2017, 33(18): 298-305.
[46] D.Lucia. Information retrieval models for recovering traceability links between code and documentation [C]. Software Maintenance, 2000. Proceedings. International Conference on. IEEE, 2000: 40-49.
[47] M.Storga, M.Darlington, S.Culley, et al. Traceability of the Development of ‘Information Objects’ in the Engineering Design Process [C]. ICORD 09: Proceedings of the 2nd International Conference on Research into Design, Bangalore, India 07.-09.01. 2009. 2009.
[48] R.Oliveto, M.Gethers, D.Poshyvanyk, et al. On the equivalence of information retrieval methods for automated traceability link recovery [C]. Program Comprehension (ICPC), 2010 IEEE 18th International Conference on. IEEE, 2010: 68-71.
[49] M.Gethers, R.Oliveto, D.Poshyvanyk, et al. On integrating orthogonal information retrieval methods to improve traceability recovery [C]. Software Maintenance (ICSM), 2011 27th IEEE International Conference on. IEEE, 2011: 133-142.
[50] H.Eyal-Salman, A.D.Seriai, C.Dony. Feature-to-code traceability in a collection of software variants: Combining formal concept analysis and information retrieval [C]. Information Reuse and Integration (IRI), 2013 IEEE 14th International Conference on. IEEE, 2013: 209-216.
[51] R.Mahajan, S.K.Gupta, R,K,Bedi. Design of software fault prediction model using BR technique [J]. Procedia Computer Science, 2015, 46: 849-858.
[52] E.Erturk, E.A.Sezer. A comparison of some soft computing methods for software fault prediction [J]. Expert Systems with Applications, 2015, 42(4): 1872-1879.
[53] 杨晶, 吴彬彬. 论网络信息溯源系统建设[J]. 新闻前哨, 2009 (5): 92-93.
[54] 时国华. 微博信息溯源及传播面分析技术的研究与实现[D]. 国防科学技术大学, 2012.
[55] 杨静, 周雪妍, 林泽鸿, 等. 基于溯源的虚假信息传播控制方法[J]. 哈尔滨工程大学学报, 2016, 37(12): 1691-1697.
[56] 刘荣叁, 张宇, 王星. 面向新浪微博的信息溯源技术研究[J]. 智能计算机与应用, 2017, 7(2): 94-98.
[57] 宋鸣. 基于流量分析的信息溯源关键技术研究[D]. 北京邮电大学, 2014.
[58] W.S.McCulloch, W.Pitts. A logical calculus of the ideas immanent in nervous activity [J]. The bulletin of mathematical biophysics, 1943, 5(4): 115-133.
[59] F.Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain [J]. Psychological review, 1958, 65(6): 386.
[60] T.J.McCabe. A complexity measure [J]. IEEE Transactions on software Engineering, 1976 (4): 308-320.
来源:中国食品行业追溯体系发展报告(2017-2018)

